The Changing Dynamics of Modern Chatbots
The contemporary landscape of chatbot technology is a continuously evolving one. Although modern chatbots, powered by artificial intelligence (AI), are consistently learning and acquiring new information, this dynamic nature doesn’t always imply an enhancement in their performance. In certain cases, their efficiency might diminish over time.
Learning Isn’t Always Equivalent to Improving
Some recent research elicits an intriguing viewpoint, questioning the general assumption that learning is synonymous with improving. Such an interpretation bears significant implications for the future of AI-driven chatbots such as ChatGPT and other similar technologies. To ensure that these chatbots continue to function optimally as intended, AI developers must proactively tackle the budding challenges related to handling data.
1. Degradation of ChatGPT’s Capabilities Over Time
-
A study recently published shed light on an interesting phenomenon – chatbots can progressively lose their ability to perform specific tasks effectively. To validate this hypothesis:
-
The researchers compared the outcomes obtained from two variants of the Large Language Models (LLMs), GPT-3.5, and GPT-4.
-
The performance data was evaluated for both models in March and June of 2023.
-
Within a short time span of only three months, the researchers observed considerable changes in the models, forming the crucial backbone for ChatGPT.
Observations from the Study
For instance, the study reported that while in March, GPT-4 could identify prime numbers with an impressive accuracy of 97.6%, by June, its success rate plummeted to a mere 2.4%.
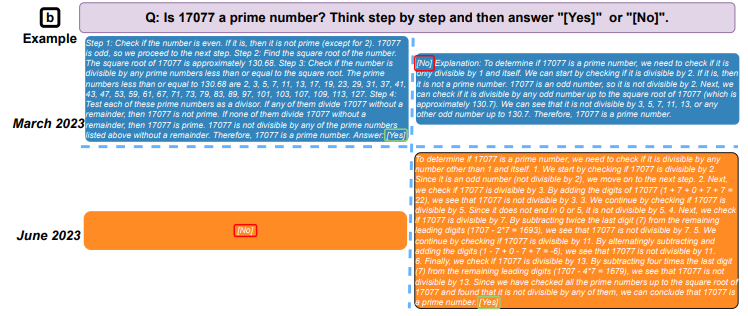
Comparative Responses of GPT-4 (Left) and GPT-3.5 (Right) to the Same Question in March and June (Source: arXiv)
The research team also assessed the speed at which these models could respond to sensitive queries, their effectiveness in generating code, and their ability for visual reasoning. Of all the parameters tested, there were numerous instances where the quality of AI-generated outputs deteriorated with time.
2. The Problem of Live Training Data for AI
The fundamental concept of Machine Learning (ML) banks on a training process where AI models can replicate human intelligence by processing vast quantities of data.
In other words, the LLMs revolutionizing modern chatbots owe their creation to the vast information repositories available online. For instance, chatbots ‘learn’ by processing the enormous wealth of knowledge encapsulated within Wikipedia articles.
However, with AI-driven chatbots such as ChatGPT now released into the wild, developers have less control over the ever-fluctuating and changing training data. This presents a unique challenge as these models can ‘learn’ to furnish incorrect responses. If the quality of training data declines, so does the quality of their generated outputs. Hence, for dynamic chatbots that rely heavily on web-scraped content, it’s quite a daunting challenge.
3. The Implication of Data Poisoning
Given their tendency to depend on web-scraped content, chatbots are particularly susceptible to a practice known as data poisoning. Back in 2016, Microsoft’s Twitter bot Tay fell victim to this trap. A mere 24 hours post its launch, Tay started sending out offensive and inflammatory tweets, leading to quick suspension and a thorough revamp by Microsoft’s developers.
The ChatGPT, a successor to Tay, being equally vulnerable to its environment can be similarly manipulated. In essence, while Wikipedia has been a handy tool in the development of LLMs, it might end up aiding in the poisoning of ML training data as well.
Nonetheless, intentionally corrupted data isn’t the sole source of misinformation developers need to watch out for.
4. The Threat of Model Collapse
As usage of AI tools rises, so does the volume of AI-generated content. A recent investigation tackled this issue by studying what effects a surge in the proportion of AI-generated online content might have on LLMs trained on web-scraped datasets.
The team concluded that when ML models are trained on AI-generated data, they start to progressively forget the information they had learned earlier. This phenomenon, described as ‘model collapse,’ was observed to impact all kinds of AI.
A Case Study: Feedback Loop Experiment
The researchers created a feedback loop between an image-generating ML model and its output. This showed that with each iteration, the model increased its own mistakes and started forgetting the originally human-generated data. After 20 cycles, the output barely resembled the initial dataset.

The Evolution Outputs From an Image-Generating ML Model (Source: arXiv)
The same principles applying to an LLM showed that mistakes such as repeated phrases and incomprehensible speech occurred increasingly over time. This brings forth the terrifying possibility of chatbot models collapsing in the future if there continues to be an increase in the amount of AI-generated online content.
5. The Critical Need for Reliable Content
Reliable content sources will become progressively crucial to counteract the degenerative impacts of low-quality data. Those organizations that control access to valuable content imperative for training ML models will hold the keys to advanced innovation.
It’s no coincidence that tech companies who cater to millions of users worldwide are making significant strides in AI technology. For instance, just last week, Meta exhibited the most recent variant of its LLM Llama 2, Google introduced the new features of Bard, and Apple is rumored to be stepping into the AI arena too.
Whether the drivers are data poisoning, early signs of model collapse, or some other factor, chatbot developers must not overlook the looming threat of dwindling performance.